|
|
概述
本文描述的关于如何实现MySQL数据库集群容器化并不是一个示例,而是一个系统工程的综述,是笔者在一家大型互联网公司的实践总结,笔者有幸带领团队从头构建了整个系统。当然笔者能力有限,如果有表述不当的地方,还请指教。
本文不会对kubernetes,容器等一些概念进行解释,适合有一定基础的同学阅读。
数据库为什么要容器化?
关于这个问题网络上的讨论很多,我在之前的一篇文章中也回应了这个问题贺大伟:数据库为什么要容器化。感兴趣的同学可以指教一下。
总体来讲,随着kubernetes和容器以及内核本身的发展,在Kubernetes上运行有状态服务的难度降低了,更重要的一定是可以借助Kubernetes强大的容器编排能力,可以通过在线离线任务混合部署来提升CPU资源的利用率,从而实现降本增效。
架构
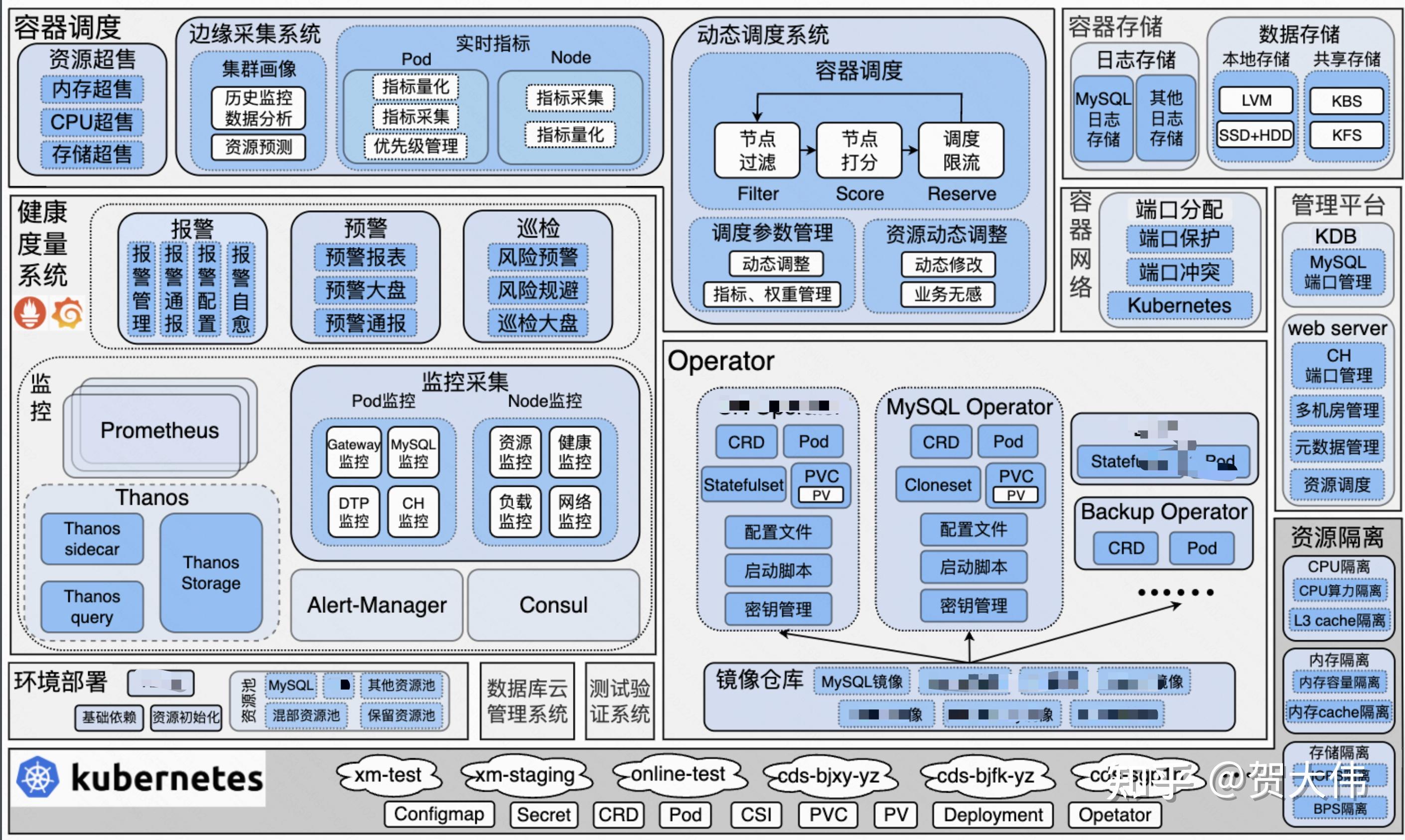
如上图所示(这图是用来装B的,当然也可能不咋滴,懒得再画一个了),整个数据库容器涉及到多个方面:
Kubernetes
这个不用多说,kubernetes提供一个抽象的分布式基础运行环境,当然我们对kubernetes的版本有一些要求,比如我们用到了StartupProbe、CSI,低版本的kubernetes无法支持。
Operator
Operator是整个容器化的核心,它负责将CR的描述转化为对kubernetes对象的管理,某种意义上讲他就是一个事件驱动的状态机。
CRD
CRD(Custom Resource Definition) 本身是一种 Kubernetes 内置的资源类型,即自定义资源的定义,用于描述用户定义的资源是什么样子。
Kubernetes自身提供的Pod,Deployment,Statefulset,Service等资源无法满足个性化复杂系统,因此kubernetes提供了CRD,这样用户就可以自己定义表达自己的资源描述,CRD必须配合Operator才能真正实现资源表达。
磁盘
很多的描述MySQL等有状态服务容器化的文章中对Volume讨论比较少,当需要工程开发的时候,Volume就是一个实实在在的挑战。当然使用云盘是一种解决方案,但是需要看到更多的考虑因素:
- 成本。云盘普遍是三副本保持,且不能跨机房,这样上层MySQL的多副本的存储成本就非常可观了
- 性能。云盘的性能一般不及本地磁盘,当然技术实力强大的云厂商有ESSD这种高性能低延迟云盘性能不是问题,主要是成本太高,玩不起。
- 本地磁盘。如果是采用本地磁盘,那么就需要自己搞一套CSI来维护管理本地磁盘,详细内容后面会展开讨论。
网络
网络对实例容器化的影响还是非常大,因为不同的网络方式决定了你实例部署的细节,比如端口管理,地址管理,甚至是探活、监控等都需要相应的适配,一点儿都不好玩。
监控报警
数据库实例运行过程中需要监控采集数据,需要报警,因此配套的监控报警系统必不可少,不然就成了睁眼瞎。但是容器环境的特殊性决定了它的监控系统也比较特殊,后面会展开讲这部分的构建。
调度
kubernetes的默认调度器是一个静态调度器,他基于资源Request和Limit来进行资源调度,这里的资源只有CPU和内存,对于一个有状态服务来说这是不够的,至少还得考虑磁盘等因素。同时有状态服务对漂移非常反感,因为拖家带口的代价有点儿大,因此这种静态的调度模型对有状态服务非常不友好。
另外我们还需要考虑混合部署来提升资源利用率,这样精细的资源治理默认调度器也难以胜任。
部署
kubernetes单集群规模有限,同时对于跨机房,跨AZ支持也不够,同时考虑到数据库集群的容灾,构建一个真正可用的数据库容器化集群,部署层面就需要考虑很多因素了:
- 节点初始化
- 节点标签管理(资源池、磁盘属性等)
- 多机房、多AZ管理
- kubernetes版本升级
- 外围系统的搭建(日志采集、基础监控等)
- 权限管理
- 存储管理(比如ceph集群)
镜像
镜像中最重要的是做很多的适配,因为MySQL依赖的运行环境比较复杂,需要安装很大的工具和组件,另外一个很有意思的事情是,需要进行容器互信,因为MySQL要进行远程物理备份,需要这种便捷的通信通路。
资源管理
kubernetes单集群规模有限,同时对于跨机房,跨AZ支持也不够,同时考虑到数据库集群的容灾,构建一个真正可用的容器环境,需要对资源进行更多的管理:
- 节点亲和隔离
- kubernetes容量管理
- 资源池管理
- 跨机房,跨AZ资源管理
资源隔离
内核Cgroup提供CPU,内存以及磁盘的隔离不太能够满足资源隔离的需求(相关的讨论网络上可以方便的查到),还需要在内核层面提供深度的隔离,同时kubernetes也需要适当的改造以配置这种隔离策略
实践
“你们要进窄门。因为引到灭亡,那门是宽的,路是大的,进去的人也多;引到永生,那门是窄的,路是小的,找着的人也少。” -- 圣经.新约.马太福音
这里我们深入讨论几个我们在实践过程中遇到的典型问题和解决之道。事实上我们的容器化之路从来没有一帆风顺,一步一个坑,一路走过来,咬牙坚持,终于看到希望和光明。
Kubernetes
对于一个熟悉kubernetes的人来说,这个不是什么值得书写的片段,不过对于一个门外汉来说,认识kubernetes是一个巨大的挑战。kubernetes中有非常多的对象(应该叫资源,kubernetes把一切视为资源),每一种对象都有自己的作用和使用场景,就像一堆积木块一样,如果用这些搭建一个可靠的系统非一朝一夕可以完成。
这里想吐槽一下很多国内写的对kubernetes资源的介绍,过于浅显,深度不够,都是玩具,很难有足够的参考价值,什么意思呢,就是当我们面对一个具体问题的时候,这些介绍和描述几乎没有什么帮助,很少有文章可以深入的阐述这些,概括的讲就是都在流于表面,干货太少。
对kubernetes认识过程基本上经历一个禅修的过程:
第一阶段:看山是山,看水是水
第二阶段:看山不是山,看水不是水
第三阶段:看山还是山,看水还是水
此中的韵味只可意会不可言传。
最好的认识kubernetes的方式就是实践+阅读代码,举个例子我们的Operator需要周期性的检查资源的状态,但是我们之前参考的框架周期比较长,都是30分钟或者十分钟,理由是这样可以减少Operator对kubernetes的压力,但是这样就导致很多时候响应不及时,因为MySQL这种系统有自己的一些逻辑,这些逻辑不能简单的反应到Pod的status种,必须周期性的轮询,同时我们发现kubernetes deployment对Pod的变更反应很快,我们也想借鉴一下,这种只能阅读源码,然后就明白了,我们也做了相应的调整实现了快速响应。
Operator
几乎所有的Operator资料都是给你展示如何使用一些自动化的工具帮你构建一个Operator框架,这个示例代码可以运行管理一个类似nginx的镜像,然而这东西就是一个玩具(可能是我比较笨),我们要解决的是一个复杂的问题,这种从简单到复杂是如何演进的没有现成的资料可以借鉴。
大家都是Kubernetes中的Deployment和Statefulset,说这个可以管理无状态或者有状态的服务,但是当我们讨论如果管理MySQL主从实例的时候,这些组件无能为力。对于MySQL,它的主从副本不对等,没办法直接使用Deployment或者Statefulset这些管理组件管理,另外对于这些副本必须要支持灵活的拓扑变更,下线等操作,这种灵活性Kubernetes自身无力满足,必须依赖Operator深度介入,因此我们采用Operator直接管理Pod的模式来实现这种灵活性。
MySQL很变态,第一次启动需要首先进行初始化,然后才能启动,另外如果是需要添加一个副本,那么首先需要进行数据拷贝,然后启动,这就带来一堆麻烦。
- 启动脚本需要适配不同场景,如何识别区分不同的场景也需要规划和设计
- MySQL物理备份的时间可能会很长,对Container的健康检查也需要适配,不然非常容易误判
- MySQL还需要保留binlog,binlog占用的存储空间也是非常可观的,磁盘申请的时候也需要考虑这一点
- 如果你使用hostnetwork,那么恭喜你,端口管理也是需要解决的麻烦
在我们的需求中,我们存在多种MySQL集群类型,不同的业务会申请不同的集群,一个集群中存在多个分片,因此一个CRD是很难搞定的,需要定义多个不同类型的CRD,因此前面提到的这种demo版本的Operator示例对于我们没啥实质价值。
幸运的是我们从其他的一些开源Operator中获得灵感,找到了Operator正确的打开方式,建议大家可以学习vitess的Operator或者tidb的Operator,都是非常优秀的,可以看到一个复杂系统的Operator如果实现的参考。
Operator这东西一旦你摸到了他的门道,后面的事情就比较顺利了。
磁盘
没有靠谱的云盘,开源的ceph性能上不满足,另外成本也高(单机房三副本),因此迫不得已,只能自研LPV CSI。
自研一个CSI并不是多困难,有一些开源的CSI可以参考,尽管不是LPV的,但是大致的流程还是一致的,可以参考实现一个。
现在真正的麻烦来了,前面提到MySQL还需要存储binlog,一种解决方案就是与数据在一个磁盘上(要是有云盘,这些都不是问题),但是主要的问题是如果这样做,那么就需要额外考虑binlog的存储,因为日志规模很大,存放在SSD磁盘上成本有点儿高,要是不差钱那当我没说。在我们的实践中日志是单独存放在HDD磁盘上的,这样就需要两块磁盘了,但是,但是,但是,LPV CSI没办法同时支持一个Pod两个PVC的调度(保证调度在一个Node上)。我们的办法是,说起来也很简单,不过需要一定的脑洞。就是只创建一个PVC,同时挂载一个hostpath,然后在PV挂载的时候,在数据盘的挂载点上创建一个软连连接到hostpath的一个目录,这个目录也是在CSI里面随机创建的(PV卸载的时候同步清理销毁),保证不会重复,这样从容器中看就是两个目录,完美解决这个难题。
互信容器
MySQL添加新副本时需要从主库远程备份一份数据到本地,那么在新添加的副本容器启动时候就需要首先干这个。
ssh -p $sshport mysql@${sourcehost} -n "/usr/local/percona-xtrabackup/8.0.26/bin/xtrabackup --defaults-file='${sourcemycnf}' --log-copy-interval=500 --user=root --port=$sourceport --password='${pass}' --slave-info --socket='${sourcesocketfile}' --parallel=1 --tmpdir='${sourcetmpdir}' --no-timestamp --backup --stream=xbstream "|xbstream -x -C $RESTORE_PATH这样就需要远程访问目标容器,因此我们需要在制作镜像的时候就考虑容器互信。他非常有价值,后面数据库的日常备份也依赖这种互信能力,否则这种容器隔离会导致很多的运维工作无法开展。
调度器
前面已经简要阐述了kubernetes默认调度器的种种不适,我们决定自研动态调度器,先看看架构图
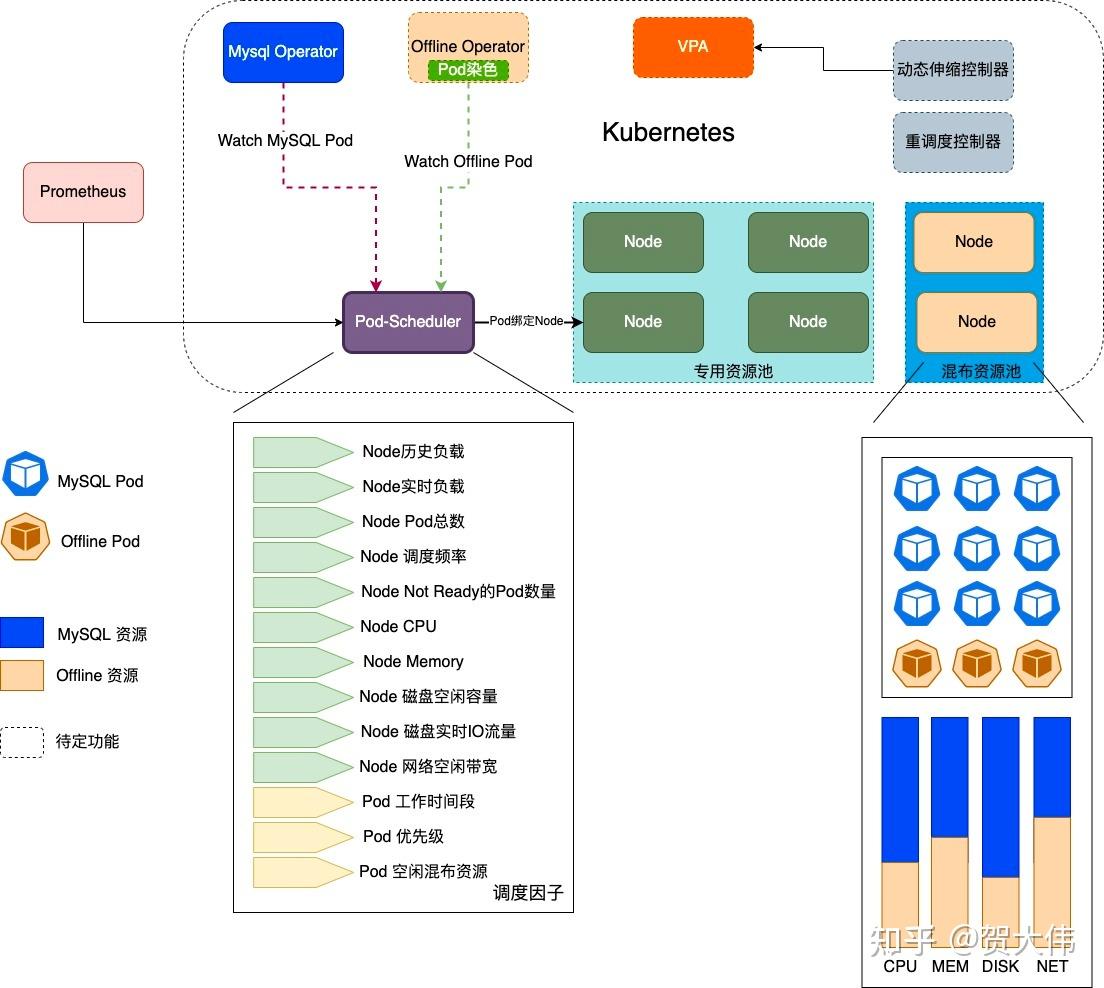
动态调度器的核心就是摈弃了资源的静态分配,通过感知Node上实时资源情况来决定如何调度。上图已经说的很清楚了,有一点我解释一下,为什么我们的动态调度器需要考虑Node上not ready的Pod的数量,这个是因为添加一个MySQL的从副本,需要首先从主副本拉取全量数据,这个阶段MySQL实例还没有启动,container还没有ready,并且这个过程可能会很长,持续几个小时都是可能的,一旦完成全量数据同步,从副本就可以启动了,接受流量了,这两个阶段对CPU,内存的需求差异非常大,如果一个Node上存在大量的not ready的Pod,那么这个Node的实际资源负载就很低,如果继续调度新的实例那么一旦Pod ready之后,资源可能就会过载。
有状态服务调度还有一个难点就是一旦调度了,就生米成为熟饭,非常难改变了,就是说你不能使用重调度这种逻辑做二次负载均衡,因为他拖家带口不方便迁移。这就要求调度器必须能够感知更多的信息来参与调度决策。
还需要补充的是,我们需要对CPU,内存,磁盘资源进行超卖,会在Node心跳时上报给kubernetes一个乘以超卖系数的一个资源数据。
关于混布我这边不展开讲,基本思路跟网络上你能检索到的文章类似,不费口舌了。
动态调度器实际的效果在MySQL场景下确实比之前静态调度器要好太多了,整体集群资源非常均匀。
网络
如果你使用一些非常好容器网络,那么这里讨论的问题不是问题。
如果你也被迫使用本地网络,那么端口管理就是一个头疼的问题。你需要明白MySQL不仅仅需要一个端口,他配套的监控采集等服务也需要端口,另外不是还有容器互信吗,那么SSHD的端口也就不能是22了,也得分配管理。说起来都是泪,我们是依赖kubernetes团队提供一种能力,就是在Pod的container启动阶段,注入环境变量的方式,由kubernetes来替我们分配一些空闲的端口,同时这些申请的端口信息也会patch到Pod上,这样Operator也可以感知到Pod实际使用的端口。
监控
数据库的监控系统构建面临两个难题:
因为kubernetes调度Pod是一个异步的过程,事先不知道他将来会运行在哪个Node上,另外后面它销毁也需要注销监控。我们的做法是单独搞了一个组件,watch所有的Pod事件,只有有新的Pod的创建就会主动注册到监控中心,如果捕获到Pod销毁,还会主动从监控中心注销,当然这还不够,还会定期校验当前所有的Pod和监控中心注册的比对,补漏注册和补充注销。
因为容器隔离的缘故,采集也是一个问题,对于MySQL server的信息采集,我们有开源的mysqld-exporter,但是还有一些外围监控,比如对binlog的监控,对数据盘的监控都需要搞,主从角色的感知等。
对于MySQL server的监控,我们采用sidecar container来解决,但是也带来了一个新问题,那就是mysqld-exporter是一个无状态服务,他本身也可以因为各种原因crash,而我们的MySQL server在运维策略上不允许重启,这样就很为难,Pod的restart策略粒度是Pod而不是container ,因为如果MySQL server运行正常,而mysqld-exporter crash了就采集不了数据了,还不能简单的重启。
我们的做法是修改kubernetes ,让他支持通过修改container ENV出发container 重启,这样就可以完美的解决了这个问题。
其他
我们不允许MySQL server不可控重启,即我们只接受那种是由管理平台发起的重启,其他情况下都不允许重启,也就是说不允许kubernetes在未授权的情况下(或者其他什么意外)重启container,或者驱逐Pod。
为了防止以为,我们在MySQL启动脚本中做了点儿手脚,可以感知这种不受控的重启,从而拒绝重启。
我们还构建了一套巡检系统,定期巡检集群的情况,对于有隐患的Node,会及时进行禁止调度等手段干预,防止调度器或者什么其他意外导致集群节点异常。
最后
大概就写这么多,其实我们做的事情很多,很庞杂,要实现一个真正可以上生产的系统还是非常不容易的,经历种种挑战和困难。
最后,欢迎同学们一起讨论 |
|


 发表于 2022-12-2 20:19:52
发表于 2022-12-2 20:19:52