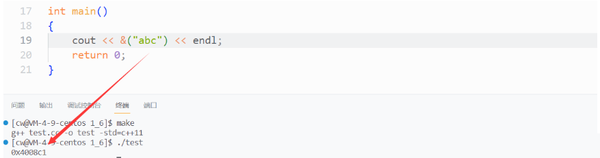
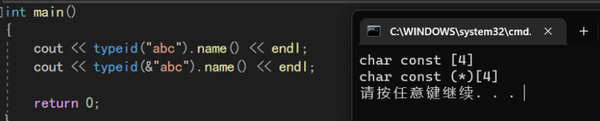
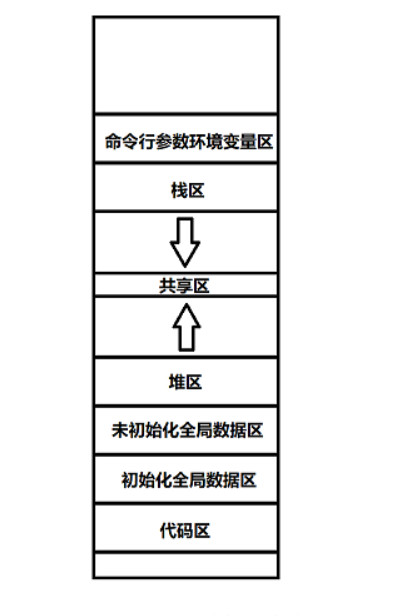
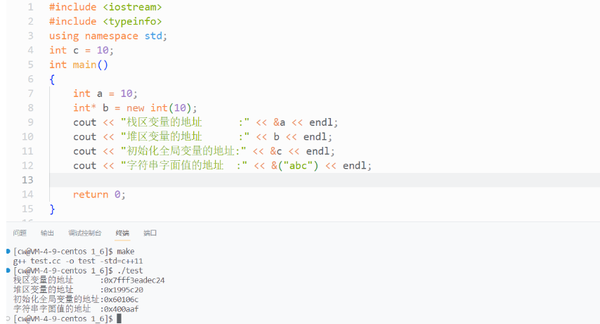
这是进程地址空间的划分,下面是低地址,上面是高地址,我们可以通过打印初始化全局数据区变量的地址,栈区变量以及堆区变量的地址,判断"abc"这个字符串是存储在哪块区域的
#include <iostream>
using namespace std;
int c = 10;
int main()
{
int a = 10;
int* b = new int(10);
cout << &#34;栈区变量的地址 :&#34; << &a << endl;
cout << &#34;堆区变量的地址 :&#34; << b << endl;
cout << &#34;初始化全局变量的地址:&#34; << &c << endl;
cout << &#34;字符串字面值的地址 :&#34; << &(&#34;abc&#34;) << endl;
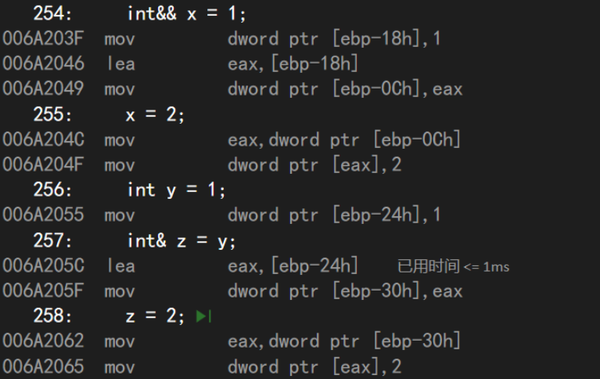
lea的意思是加载有效的偏移量地址,先看左值引用的那三行代码,int y = 1是将1放到ebp-24h这个地址处,int& z = y则是创建y的引用z,我们知道引用的本质是与地址建立映射关系,那么这个映射关系当然就需要保存了,创建引用的第一条汇编就是将ebp-24h这个偏移地址存储到eax寄存器中,ebp-24h这个偏移地址上存储的是什么呢?从int y = 1的汇编可以得知ebp-24h这个地址与变量y的地址相同,存储的是1。再看创建引用的第二条汇编,将eax中存储的数据移动到ebp-30h中,eax存储的不就是变量y的地址吗,将y的地址存储到ebp-30h不就是映射关系的保存吗?由于x86架构的系统有32位的地址,所以y的地址被存储到dword类型(双字,32比特)的地址上。再看最后一行代码z = 2,它的汇编有两条,第一条是将ebp - 30h地址处的数据移动到eax寄存器中,也就是将变量y的地址,存储1的地址移动到eax寄存器中,最后再将2移动到eax保存的地址处。这么看来,虽然在C++中我们没有显式的书写指针,但是在汇编层面依然是需要使用指针的,可以说从汇编的角度看,引用与指针没有任何区别,指针保存了变量的地址,引用需要保存与被引用对象的地址的映射关系,但这也是地址啊,我们通过引用找到被引用对象的地址,不就是引用与被引用对象之间建立起了映射关系吗?引用和指针都是保存对象的地址,那么两者有区别吗?很好理解,虽然两者的底层相同,但是在高级语言的层面上,引用是对地址的一种封装,而指针呢?指针没有封装地址,直接保存了地址,将地址暴露了出来。
再看右值引用的两行代码,int&& x = 1是创建一个右值引用,引用1这个字面常量,我们知道程序编译后,字面常量被存储在代码区,代码区对我们来说是只读的,我们不能修改上面的数据,而引用呢,引用是对地址的一种封装,但是引用可以封装一个只读数据区的地址吗?当然不能,你也没见过&1这样的表达式吧,那么引用封装的地址又是什么地址呢?由于只读数据区的数据不能修改,所以编译器会将代码翻译为:先在可写数据区创建只读数据的一份拷贝,再把这份拷贝的地址给引用,让引用封装这个地址。所以我们通过引用修改的数据,只是只读数据的一份拷贝,并不是真正的只读数据。因此第一条汇编就是将1移动到ebp-18h地址处,显然这是在栈上开辟了空间存储1,接着再把1的偏移地址ebp-18h加载到eax寄存器中,最后把eax寄存器的数据移动到ebp-0ch地址处。可以看出,int&& x = 1这条代码干了两件事,一是int x = 1在栈区创建一个int变量存储1,然后再将存储1的地址保存到栈区的另一块空间,作为引用的映射关系保存,仔细一看,第二件事不就是左值引用的创建过程吗?
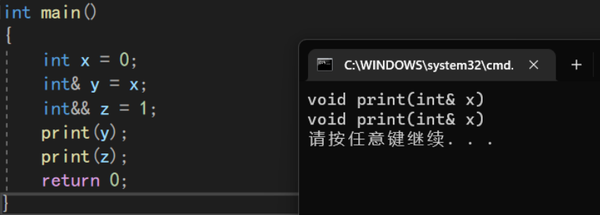
右值引用是右值吗???
int main()
{
int x = 0;
int& y = x;
int&& z = 1;
print(y);
print(z);
return 0;
}
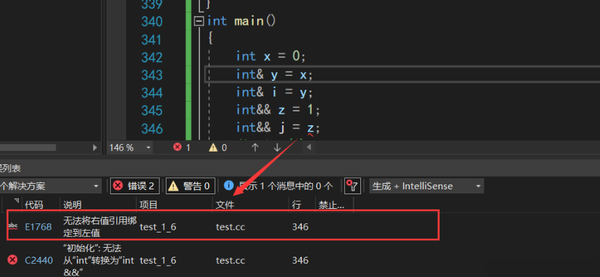
print有两个重载的版本,一个是形参类型为左值引用,一个为右值引用,将左值引用y作为print的参数,调用的是形参为左值引用的print,这没什么问题,那么将右值引用z作为print的形参,会调用形参为右值引用的print吗?


 发表于 2023-4-19 15:49:32
发表于 2023-4-19 15:49:32