|
|
Modern C++ Standards
C++ 越来越酷炫和复杂了,C++20 被认为是自 C++11 以来的最大的一次更新
什么,你连 C++11 都还没开始用呢,那赶紧吭哧吭哧学起来吧
知乎上反响似乎不错,未来会分篇,还是按照 cpp 标准的顺序更新更酷更全的 cpp 特性!
C++11
auto type deduction
多数时候我们不关心类型叫什么,只关心它的行为。C++11 引入了 auto 关键字,可以让编译器自动推导出变量的类型。auto 可以用于函数返回值,也可以用于变量声明。一般我们建议有了 auto 以后,能用 auto 都用 auto
auto x = 1;
range-based for loop
C++11 引入了 range-based for loop,可以用于遍历容器。搭配 auto 非常舒服
std::vector< std::vector<int> > vv;
for(auto v : vv) { // range-based for loop
for(auto i : v) {
std::cout << i << std::endl;
}
}
lambda expression
有些函数需要传递函数指针作为参数,但是这个函数只会在这个地方被调用一次。C++11 引入了 lambda expression,可以让我们在调用的地方定义这个函数。lambda expression 的语法是 [capture](parameters) -> return_type { body },其中 capture 是捕获列表,parameters 是参数列表,return_type 是返回值类型,body 是函数体。捕获列表可以捕获外部变量,也可以捕获 this 指针。如果不需要捕获任何变量,可以省略捕获列表。如果不需要指定返回值类型,可以省略返回值类型。如果不需要指定参数列表,可以省略参数列表。如果不需要指定函数体,可以省略函数体,这时候函数体只有一行,就是返回值。
old style
bool is_even(int x){
return x % 2 == 0;
}
std::vector<int> v = { 1, 2, 3, 4, 5 };
auto counteven = std::count_if(std::begin(v), std::end(v), is_even);
std::cout << &#34;The number of even vector elements is: &#34; << counteven;
new style
std::vector<int> v = { 1, 2, 3, 4, 5 };
auto counteven = std::count_if(std::begin(v), std::end(v),
[](int x) {return x % 2 == 0; }); // lambda expression
std::cout << &#34;The number of even vector elements is: &#34; << counteven;
enum class
枚举类型是一种特殊的整型类型,它的值只能是枚举类型的成员。C++11 引入了 enum class,可以让枚举类型的值只能在枚举类型的作用域内使用。如果不使用 enum class,枚举类型的值可以在枚举类型的作用域外使用,这可能会造成命名冲突。
enum class MyEnum
{
myfirstvalue,
mysecondvalue,
mythirdvalue
};
int main()
{
MyEnum myenum = MyEnum::myfirstvalue;
}
smart pointers
智能指针解决了以往声明指针之后一定要自己管理内存比如 delete 的问题。它会在判断这个指针不再被使用的时候自动释放内存。C++11 引入了四种智能指针,分别是 unique_ptr, shared_ptr, weak_ptr, 和 auto_ptr。unique_ptr 是独占所有权的智能指针,shared_ptr 是共享所有权的智能指针,weak_ptr 是弱引用的智能指针(解决循环拥有的问题),auto_ptr 是 unique_ptr 的替代品,但是它不是线程安全的。
#include <memory>
int main()
{
std::shared_ptr<int> p1 = std::make_shared<int>(123);
// std::shared_ptr<int> p1(new int{ 123 });
std::shared_ptr<int> p2 = p1;
std::shared_ptr<int> p3 = p1;
} // when the last shared pointer goes out of scope, the memory gets
// deallocated
另外,智能指针更推荐而且只推荐的构造方法是 std::make_shared,std::make_unique 这些,一方面,它避免了多调用一次拷贝构造。更重要的是,如果不慎用原始指针重复构造智能指针,会造成内存泄漏。比如下面的代码,p1 和 p2 都指向同一个内存,但它们彼此不知道对方的存在,当 p2 被析构的时候,p1 也会被析构,之后再调用 p1 就会内存泄漏。
#include <memory>
int main(){
auto p = new int{ 123 };
std::shared_ptr<int> p1(p);
std::shared_ptr<int> p2(p);
}
tuple
我们经常希望函数返回多个值,过去我们需要定义一个结构体,但现在我们有更简单的方式。
值得注意的是之前已经有了 std::pair 可以存储两个值,std::tuple 是它的升级版,可以存储任意多个类型的值。
它的定义和提取方法如下:
#include <utility>
#include <tuple>
int main()
{
std::tuple<char, int, double> mytuple = { &#39;a&#39;, 123, 3.14 };
// or std::make_tuple(&#39;a&#39;,123,3.14)
std::cout << &#34;The first element is: &#34; << std::get<0>(mytuple) << &#39;\n&#39;;
std::cout << &#34;The second element is: &#34; << std::get<1>(mytuple) << &#39;\n&#39;;
std::cout << &#34;The third element is: &#34; << std::get<2>(mytuple) << &#39;\n&#39;;
}
C++17 有了更方便的解包方法,C++11 中提供的是 std::tie,感兴趣的可以去搜索,但我建议直接用下文 C++17 的解包方法
thread
C++11 引入了多线程,包含锁和线程两个最常用的功能
#include <iostream>
#include <thread>
#include <string>
#include <mutex>
std::mutex m; // will guard std::cout
void myfunction(const std::string& param)
{
for (int i = 0; i < 10; i++)
{
std::lock_guard<std::mutex> lg(m);
std::cout << &#34;Executing function from a &#34; << param << &#39;\n&#39;;
} // lock_guard goes out of scope here and unlocks the mutex
}
int main()
{
std::thread t1{ myfunction, &#34;Thread 1&#34; };
std::thread t2{ myfunction, &#34;Thread 2&#34; };
t1.join();
t2.join();
}
nullptr
C++11 引入了 nullptr,它是一个空指针的类型,可以用来初始化指针。它的出现解决了 C++ 中 NULL 二义性的问题,因为事实上 NULL 在 C++ 中被 define 为了 0,所以如果我们的某个函数有一个参数是 int,那么 NULL 也可以传进去,然而我们没有办法区分这个 NULL 是不是一个指针。
void myfunction(int i) { std::cout << &#34;myfunction(int)\n&#34;; }
void myfunction(char* c) { std::cout << &#34;myfunction(char*)\n&#34;; }
int main()
{
myfunction(NULL); // ambiguous
myfunction(nullptr); // calls myfunction(char*)
}
Type Aliases
C++11 引入了 using 关键字,可以用来定义类型别名。它相较于 typedef 或者 define 的优势在于可以使用模板。
template <typename T>
using MyVector = std::vector<T, MyAllocator<T>>;
int main()
{
MyVector<int> v;
}
右值引用 &&
右值往往是计算后马上要销毁的值,所以它不存在地址,也无法引用。
一个经典场景是我们写了一个矩阵类,我们想要输出一个矩阵,矩阵很大所以我们想要避免拷贝
void output(const Matrix& m)
{
// do something
}
然而在调用 output(m*m) 的时候就报错了,因为 m*m 是一个右值,所以我们可以再重载一个右值引用 const Matrix&& m
void output(const Matrix&& m)
{
// do something
}
std::move
可以把左值转化为右值
一个经典的场景是我们想要把一个对象的所有权转移给另一个对象,我们可以这样做:
Rvalue a = &#34;hello&#34;;
Rvalue b = std::move(a);
// a is now empty
这样可以避免一次拷贝,直接把b的所有权转移给a,然后a就是空的了。
然而这样做有效的前提是 Rvale 这个类有定义移动拷贝,它本质上是一种全新的构造方法,比如:
class MyString
{
public:
MyString(const char* str)
{
m_data = new char[strlen(str) + 1];
strcpy(m_data, str);
}
MyString(const MyString& str)
{
m_data = new char[strlen(str.m_data) + 1];
strcpy(m_data, str.m_data);
}
MyString(MyString&& str) noexcept // move constructor
{
m_data = str.m_data;
str.m_data = nullptr;
}
~MyString()
{
delete[] m_data;
}
char* m_data;
}
标准库里面的 std::string 就是类似这样实现的。
STL
这里补充一些很好用的 STL
std::array
用来替代传统数组
std::array<int,50> arr; 等价于 int arr[50];
不同的是,std::array 是一个类,所以它有很多方法,比如 arr.size(),arr.empty(),arr.fill(0) 等等,另外它可以方便地复制,还可以用 range-based for 循环
using D2Array = std::array<std::array<MyClass, 50>, 50>; 可以方便地给二维数组起别名,比如创建一个棋盘,这样复制就很方便了。
std::unordered_map
std::unordered_map 是一个哈希表,在数据量适中的时候,它的查询速度非常快,比 std::map 快很多,唯一的缺点是它需要对应的类型具有 std::hash 的特化,比如 std::string,int,double 等等,但是自定义的类就需要自己实现 std::hash 的特化,而这个hash函数可能并不容易写好:
以下是一个糟糕的例子,但是可以用来演示,实际中得找更好的hash函数
auto hash_pair = [](const std::pair<int, int>& p) {
return std::hash<int>()(p.first) ^ std::hash<int>()(p.second);
};
std::unordered_map<std::pair<int, int>, bool, hash_pair> um;
std::chrono
过去我们用 clock() 可以在毫秒尺度上计时,现在我们可以在微妙尺度上计时啦
#include <chrono>
using namespace std;
using namespace chrono;
int main(){
auto start = system_clock::now();
// do something...
auto end = system_clock::now();
auto duration = duration_cast<microseconds>(end - start);
cout << double(duration.count()) * microseconds::period::num / microseconds::period::den <<&#34;s&#34;;
}
better random
过去的随机数 rand() 有很多问题,比如
- 生成的数字太小
- 没办法指定范围
- 没办成生成正态分布等其他随机分布
- 没办法生成浮点数
这些问题在 C++11 都得到了解决
随机算法
简单说现在 C++11 实现了多个随机数算法,每个算法是一个模板类,如果不清楚用 default_random_engine 就好了
- linear_congruential_engine 线性同余法
- mersenne_twister_engine 梅森旋转法
- subtract_with_carry_engine 滞后Fibonacci
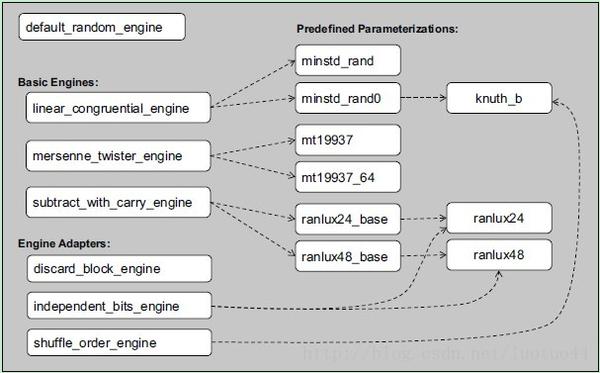
img
转载自 https://blog.csdn.net/luotuo44/article/details/33690179
demo
其他功能直接先看看 demo 吧
#include <iostream>
#include <iomanip>
#include <string>
#include <map>
#include <random>
#include <cmath>
int main()
{
// Seed with a real random value, if available
std::random_device r;
// Choose a random mean between 1 and 6
std::default_random_engine e1(r());
std::uniform_int_distribution<int> uniform_dist(1, 6);
int mean = uniform_dist(e1);
std::cout << &#34;Randomly-chosen mean: &#34; << mean << &#39;\n&#39;;
// Generate a normal distribution around that mean
std::seed_seq seed2{r(), r(), r(), r(), r(), r(), r(), r()};
std::mt19937 e2(seed2);
std::normal_distribution<> normal_dist(mean, 2);
std::map<int, int> hist;
for (int n = 0; n < 10000; ++n) {
++hist[std::round(normal_dist(e2))];
}
std::cout << &#34;Normal distribution around &#34; << mean << &#34;:\n&#34;;
for (auto p : hist) {
std::cout << std::fixed << std::setprecision(1) << std::setw(2)
<< p.first << &#39; &#39; << std::string(p.second/200, &#39;*&#39;) << &#39;\n&#39;;
}
}
详细的功能见 https://en.cppreference.com/w/cpp/numeric/random
C++14
better auto
现在函数返回值都不用指定了,这也是为什么我们建议万物皆 auto
auto myintfn() // integer
{
return 123;
}
auto mydoublefn() // double
{
return 3.14;
}
int main()
{
auto x = myintfn(); // int
auto d = mydoublefn(); // double
}
better lambda
可以在 lambda 中使用 auto 了
#include <iostream>
int main()
{
auto mylambda = [](auto p) {std::cout << &#34;Lambda parameter: &#34; << p <<
&#39;\n&#39;; };
mylambda(123);
mylambda(3.14);
}
C++17
structured bindings
C++ 中令 python 程序员狂喜的特性,可以直接用 auto 来解包 tuple 和 pair 甚至数组了。另外 auto 是复制的,所以如果你想要引用的话,可以用 auto&。
数组
int main()
{
int arr[] = { 1, 2, 3 };
auto [myvar1, myvar2, myvar3] = arr;
}
std::vector 以及 auto&
int main()
{
std::vector<int> v = { 1, 2, 3 };
auto& [myvar1, myvar2, myvar3] = v;
}
filesystem
简单说,现在 C++ 可以处理文件,路径等等东西了
std::string_view
简单说它是只读的 string
C++ 的字符串处理系统里面过去一直是两大体系,一个是 char s[100] = &#34;hello world&#34; 另一个是 std::string s = &#34;hello world&#34;。多数时候我们喜欢 std::string,因为它提供了强大的各种库函数,比如查找,转换,获取字符串长度。
然而在实际生产环境中遇到了这么几个问题 std::string 处理不好的:
- 取子串,比如 std::string s = &#34;hello world&#34;; std::string sub = s.substr(5, 10);,这个操作会创建一个新的字符串,然后把原来的字符串的一部分拷贝过去,这个操作是非常昂贵的,因为它需要申请内存,然后拷贝,然后释放内存,然而如果是 char*,只要把指针向后移动即可。
- 内存碎片,std::string 的内存是分配在堆上的,函数调用的时候会反复的申请和释放内存,这样会导致内存碎片,导致内存分配变慢。
std::string_view 于是被设计用来替代 const std::string&。它只负责管理一个数据指针,而不拷贝数据,这样的设计模式可以解决很多 std::string 中的问题,总之你想用 const std::string& 的时候,换成 std::string_view 吧!
#include <iostream>
#include <string>
#include <string_view>
int main()
{
std::string s = &#34;Hello World&#34;;
std::string_view sw(s);
std::cout << sw.substr(0, 5);
}
std::any
C++ 中另一令 python 程序员狂喜的特性,“动态”类型
它可以动态地分配小对象,从今往后 C++ 也可以自诩拥有动态类型了
std::any a; // a is empty
std::any b = 4.3; // b has value 4.3 of type double
a = 42; // a has value 42 of type int
b = std::string{&#34;hi&#34;}; // b has value &#34;hi&#34; of type std::string
if (a.type() == typeid(std::string))
{
std::string s = std::any_cast<std::string>(a);
useString(s);
}
else if (a.type() == typeid(int))
{
useInt(std::any_cast<int>(a));
}
std::optional
很多时候我们定义一个函数,我们希望有些参数是可选的。过去我们会使用特殊值来标记
然而这样的缺点很明显
- 如果是指针,不传指针和传空指针显然是两件事,但是我们无法区分
- 如果是整数,假设我们约定 0 是空,但是如果用户真的想传 0,我们也无法区分
- 如果是 std::string,它无法隐式转换为bool,所以你没办法用 if(s) 来判断它是不是“空”,你还真得用一个奇怪的特殊值来表示,事情更加丑陋了起来
所以 C++17 引入了 std::optional 来解决这个问题。
void test(std::optional<unsigned> opt){
if (opt.has_value()) {
std::cout << opt.value() << std::endl;
}
else{
std::cout << &#34;no value&#34; << std::endl;
}
}
void test2(std::optional<unsigned> opt){
if (opt) {
std::cout << *opt << std::endl;
}
else{
std::cout << &#34;no value&#34; << std::endl;
}
}//也可以写成指针风格,std::optional 重载了 operator* 和 operator->
int main() {
std::optional<unsigned> opt; //默认构造是空
test(opt);
opt = 10;
test(opt);
opt = std::nullopt;
test(opt);
}
std::variant
它是 union 的升级版。过去 union 只负责管理数值,但不负责管理类型,所以你并不知道某一时刻 union 里面的值是什么类型,用不对应的类型去操作它会导致未定义行为
使用 std::variant 就可以在这种时候报错
#include <iostream>
#include <variant>
int main()
{
std::variant<char, int, double> myvariant{ &#39;a&#39; }; // variant now holds
// a char
std::cout << std::get<0>(myvariant) << &#39;\n&#39;; // obtain a data member by
// index
std::cout << std::get<char>(myvariant) << &#39;\n&#39;; // obtain a data member
// by type
myvariant = 1024; // variant now holds an int
std::cout << std::get<1>(myvariant) << &#39;\n&#39;; // by index
std::cout << std::get<int>(myvariant) << &#39;\n&#39;; // by type
myvariant = 123.456; // variant now holds a double
}
std::byte
过去我们常常用 unsigned char 来表示字节,然而其实它只是一个整数而已,你可以对它加减乘除。
现在 C++ 有了 std::byte 来表示字节,你只可以对它进行位运算,常规整数计算会报错。
在你希望使用“子节”这个类型的时候,std::byte 可以让你的程序更安全,更清晰,更装逼。
std::invoke, std::apply, std::function, std::bind
这些函数来自 C++17 及以前的标准,但我们放在一起讲。
struct Foo {
Foo (int num) : num_(num){}
int addwith (int i,int j) const { return num_ + i + j; }
int num_ ;
} ;
int main()
{
std::function<int(const Foo&, int, int)> add = &Foo::addwith;
Foo foo(0);
std::cout << std::apply(add, std::pair(foo, 1, 2)) << &#39;\n&#39;;
std::cout << std::invoke(add, foo, 11, 22) << &#39;\n&#39;;
auto addwith2 = std::bind(add, foo, 2, std::placeholders::_1);
std::cout << addwith2(3);
}
std::invoke, std::apply 都是用来调用函数的,区别是参数的传入方式,std::apply 是传入一个 tuple
std::function 是函数指针的替代品,它可以接受 lambda 表达式,而过去的函数指针不能,另外它还是 std::bind 的返回类型
std::bind 是用来绑定函数参数的,std::placeholders::_1 代表占位符,占第一个位置(从1开始),所以 std::bind 做的事情就是填充部分参数,剩余空的参数用占位符占位,然后生成一个新函数,新函数的参数就会对应地填到占位符里面。
std::ref, std::cref
这事实上是 C++11 的内容,但是放在 bind 之后讲。
如果 std::bind 的函数的参数是引用,我们需要显式地用 std::ref 或者 std::cref 来包装一下,否则会被当成值传递。
一般情况下这可以被隐式转换,所以不需要使用这两个函数。
#include <functional>
#include <iostream>
void f(int& n1, int& n2, const int& n3)
{
std::cout << &#34;In function: &#34; << n1 << &#39; &#39; << n2 << &#39; &#39; << n3 << &#39;\n&#39;;
++n1; // increments the copy of n1 stored in the function object
++n2; // increments the main()&#39;s n2
// ++n3; // compile error
}
int main()
{
int n1 = 1, n2 = 2, n3 = 3;
std::function<void()> bound_f = std::bind(f, n1, std::ref(n2), std::cref(n3));
n1 = 10;
n2 = 11;
n3 = 12;
std::cout << &#34;Before function: &#34; << n1 << &#39; &#39; << n2 << &#39; &#39; << n3 << &#39;\n&#39;;
bound_f();
std::cout << &#34;After function: &#34; << n1 << &#39; &#39; << n2 << &#39; &#39; << n3 << &#39;\n&#39;;
}
C++20
这个太过于新,甚至有些功能编译器都还没实现,目前实际在使用的最新的标准是 C++17,C++20 就让我们囫囵吞枣一下吧
Modules
类似 Python 的包,它被用来加速编译,增加封闭性
better template
在使用模板的时候,如果对应类型不支持我们想要的操作,它的报错有时候会很奇怪。我们现在可以在定义模板之前要求使用这个模板的类型必须支持某些操作,否则编译器会报错。
#include <iostream>
#include <concepts>
template <typename T>
concept MustBeIncrementable = requires (T x) { x ++; };
template<MustBeIncrementable T>
void myfunction(T x)
{
x += 1;
std::cout << x << &#39;\n&#39;;
}
int main()
{
myfunction<char>(42); // OK
myfunction<int>(123); // OK
myfunction<double>(345.678); // OK
}
Lambda Templates
如字面意思,lambda 表达式可以用模板了
ranges library
挺酷的,直接看代码吧,重点在 auto result = ...
#include <iostream>
#include <ranges>
#include <vector>
int main() {
using std::views::filter,
std::views::transform,
std::views::reverse;
// Some data for us to work on
std::vector<int> numbers = { 6, 5, 4, 3, 2, 1 };
// Lambda function that will provide filtering
auto is_even = [](int n) { return n % 2 == 0; };
// Process our dataset
auto results = numbers | filter(is_even)
| transform([](int n){ return n++; })
| reverse;
// Use lazy evaluation to print out the results
for (auto v: results) {
std::cout << v << &#34; &#34;; // Output: 2 4 6
}
}
C++23
看到两张神图


总之 C++20 是一栋漂亮的大楼,那 C++23 就是修修 BUG 把大楼建出来吧
本文使用 WPL/s 发布 @GitHub
|
|


 发表于 2023-1-10 10:03:22
发表于 2023-1-10 10:03:22