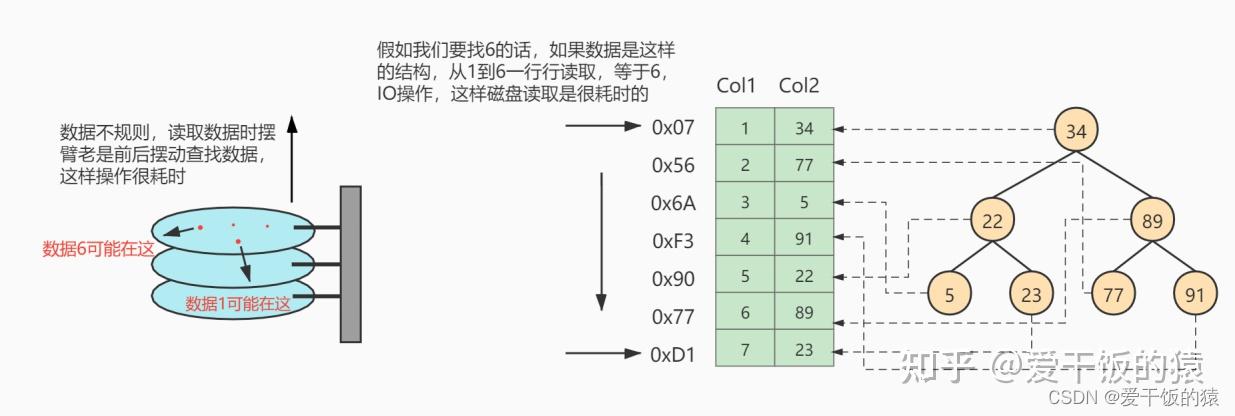
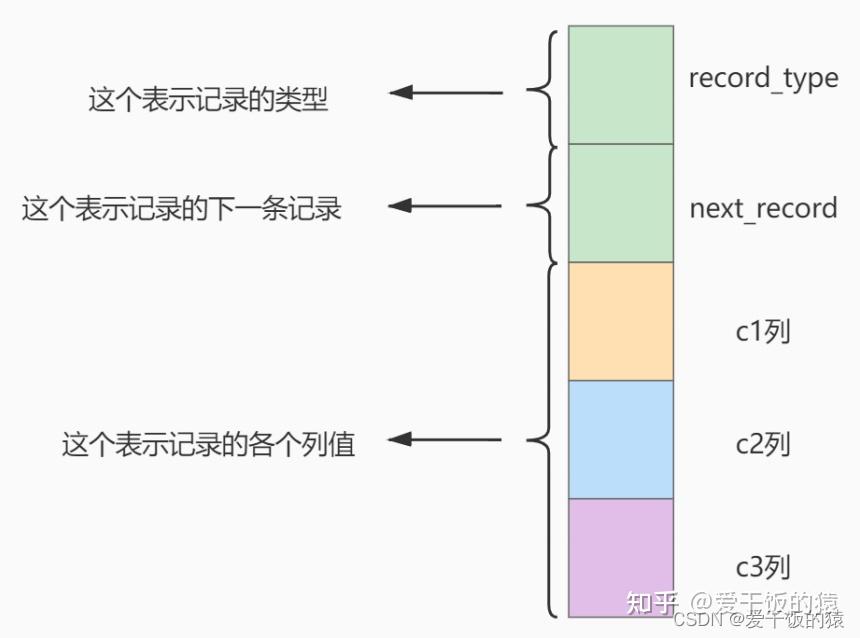
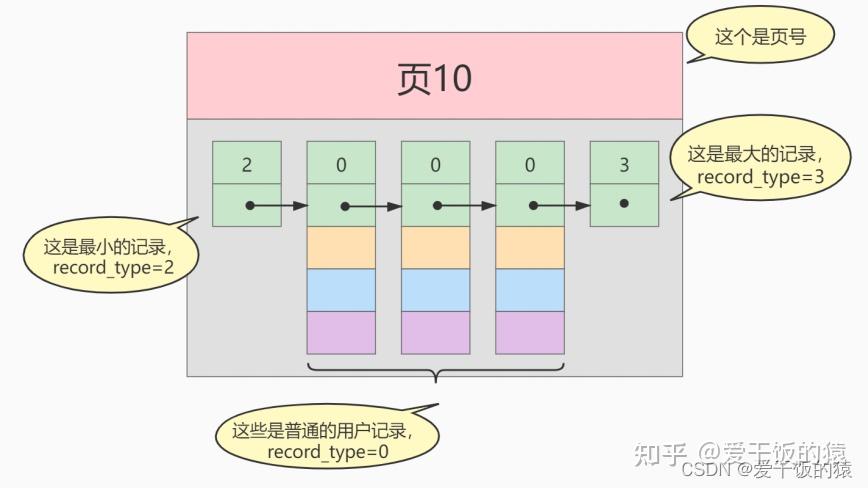
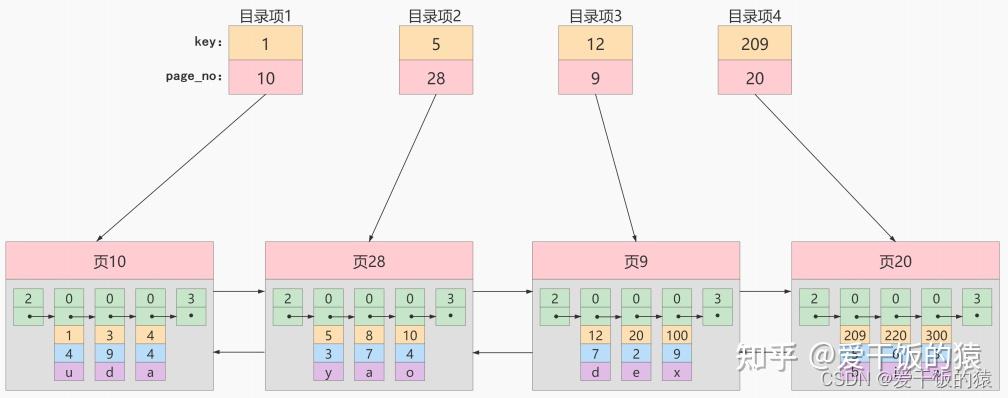
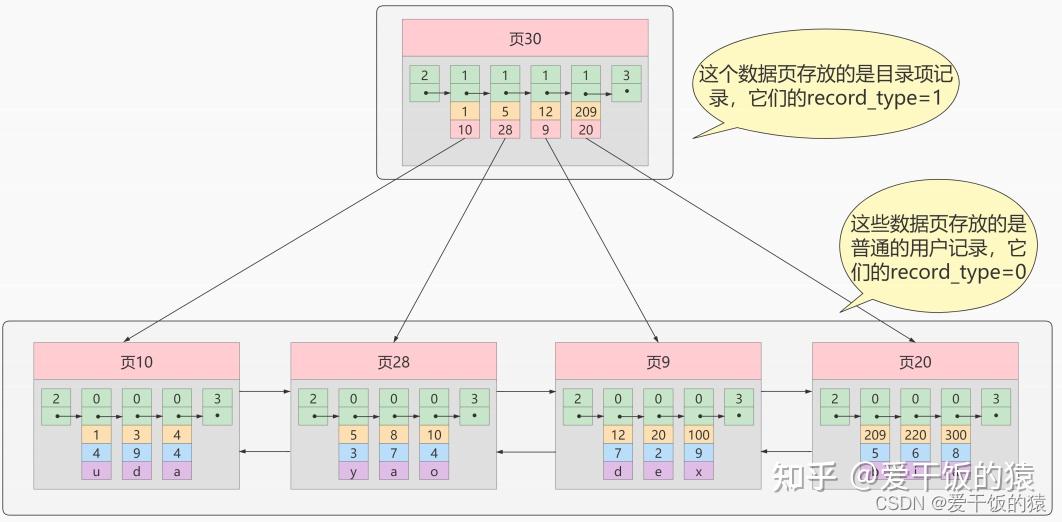
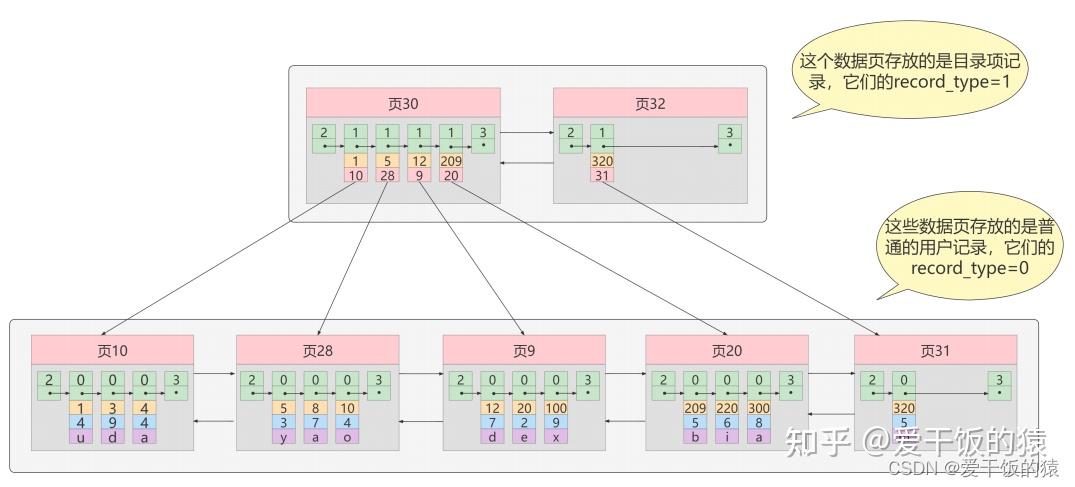
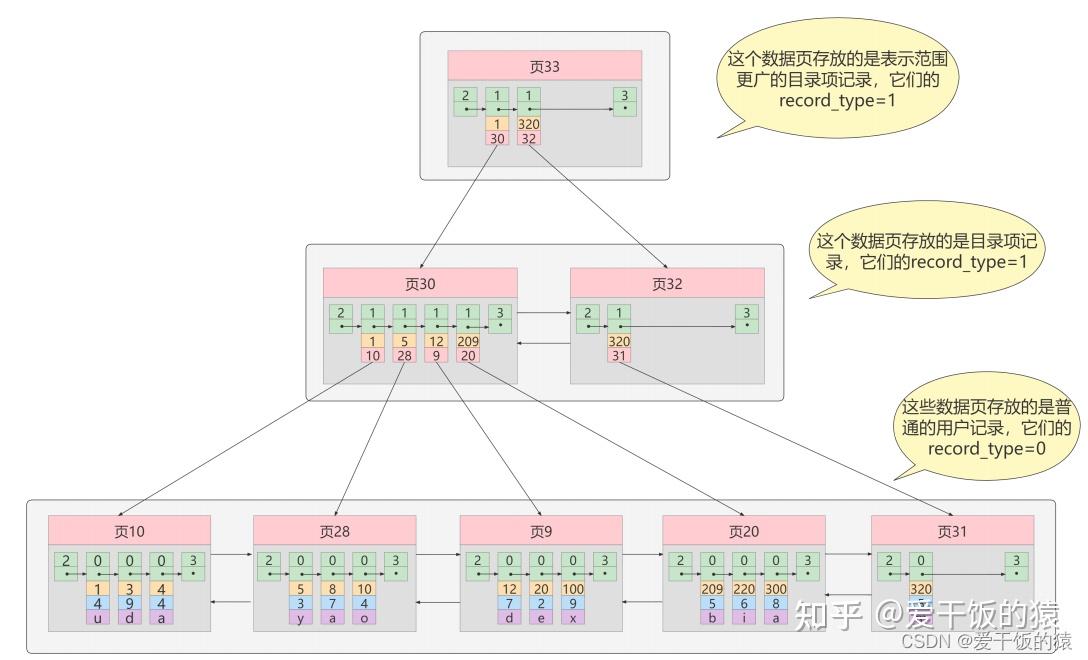
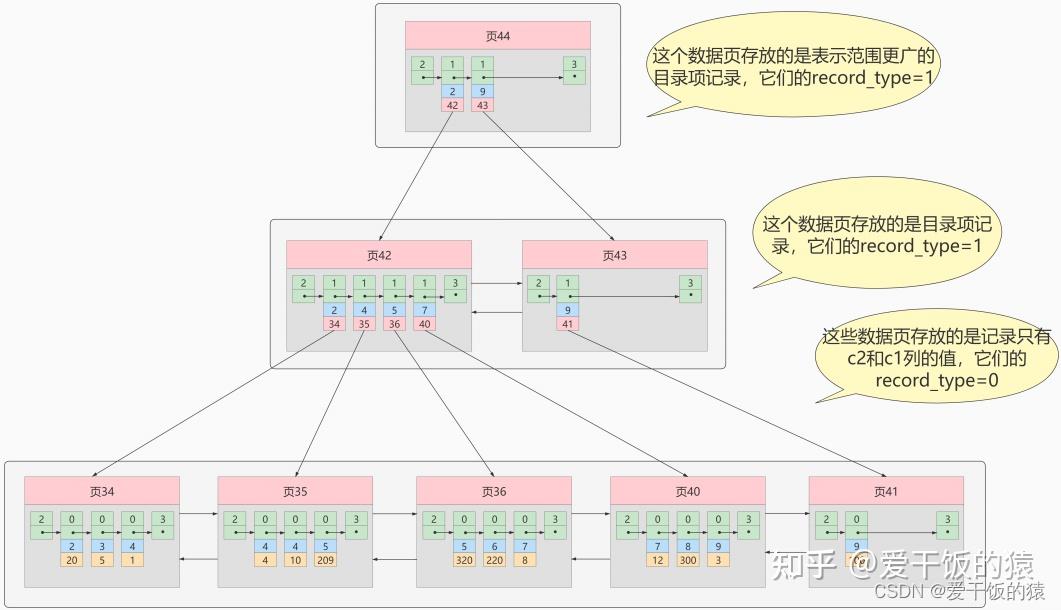
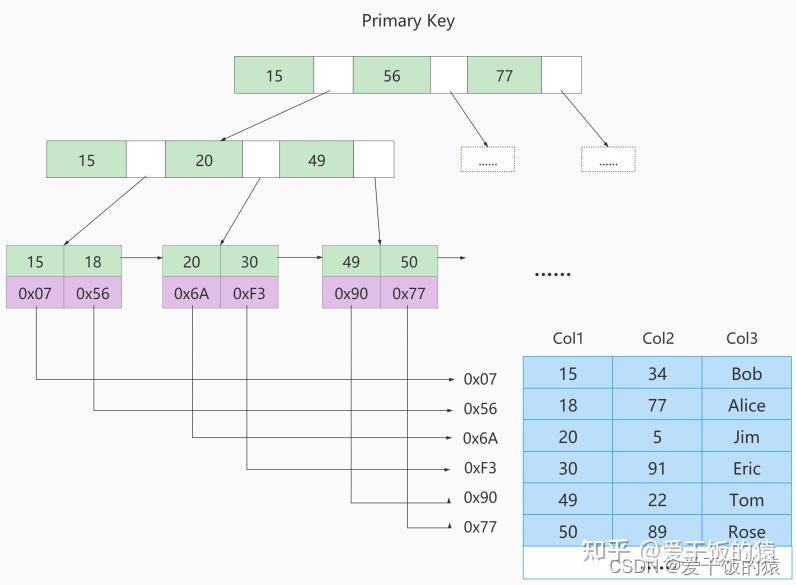
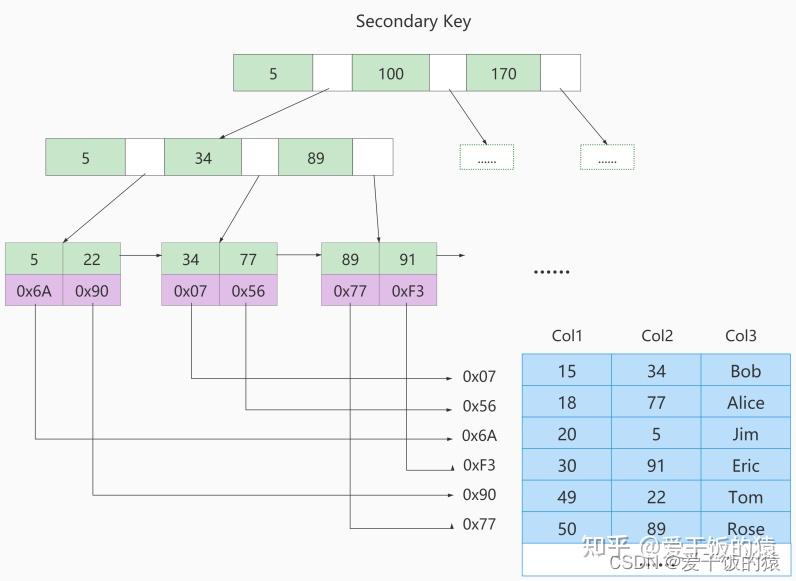
MyISAM的索引方式都是“非聚簇”的,与InnoDB包含1个聚簇索引是不同的。 小结两种引擎中索引的区别:
① 在InnoDB存储引擎中,我们只需要根据主键值对聚簇索引进行一次查找就能找到对应的记录,而在MyISAM中却需要进行一次回表操作,意味着MyISAM中建立的索引相当于全部都是二级索引。
② InnoDB的数据文件本身就是索引文件,而MyISAM索引文件和数据文件是分离的,索引文件仅保存数据记录的地址。
③ InnoDB的非聚簇索引data域存储相应记录主键的值,而MyISAM索引记录的是地址。换句话说,InnoDB的所有非聚簇索引都引用主键作为data域。
④ MyISAM的回表操作是十分快速的,因为是拿着地址偏移量直接到文件中取数据的,反观InnoDB是通过获取主键之后再去聚簇索引里找记录,虽然说也不慢,但还是比不上直接用地址去访问。
⑤ InnoDB要求表必须有主键(MyISAM可以没有)。如果没有显式指定,则MySQL系统会自动选择一个可以非空且唯一标识数据记录的列作为主键。如果不存在这种列,则MySQL自动为InnoDB表生成一个隐含字段作为主键,这个字段长度为6个字节,类型为长整型。 5. 索引的代价
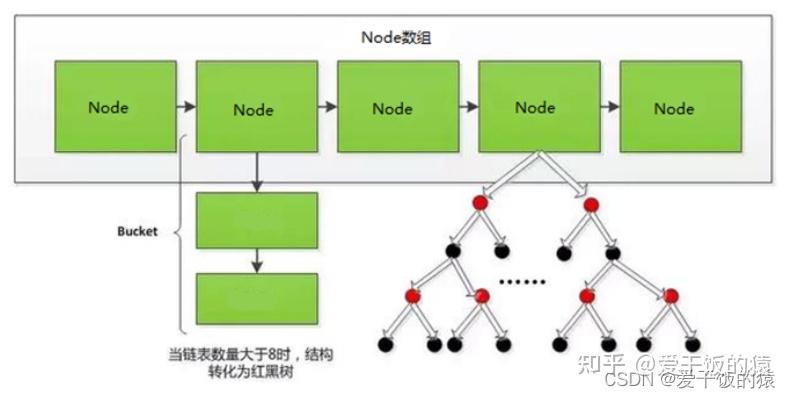
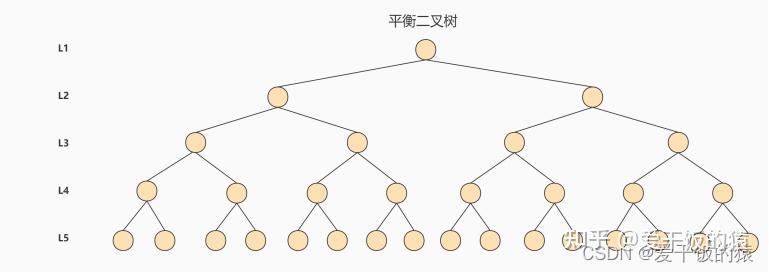
1、Hash索引不能进行范围查询,而B+树可以。这是因为Hash索引指向的数据是无序的,而B+树的叶子节点是个有序的链表。
2、Hash索引不支持联合索引的最左侧原则(即联合索引的部分索引无法使用),而B+树可以。对于联合索引来说,Hash索引在计算Hash值的时候是将索引键合并后再一起计算Hash值,所以不会针对每个索引单独计算Hash值。因此如果用到联合索引的一个或者几个索引时,联合索引无法被利用。
3、Hash索引不支持 ORDER BY 排序,因为Hash索引指向的数据是无序的,因此无法起到排序优化的作用,而B+树索引数据是有序的,可以起到对该字段ORDER BY 排序优化的作用。同理,我们也无法用Hash索引进行模糊查询,而B+树使用LIKE进行模糊查询的时候,LIKE后面后模糊查询(比如%结尾)的话就可以起到优化作用。
4、InnoDB不支持哈希索引 思考题:Hash 索引与 B+ 树索引是在建索引的时候手动指定的吗?


 发表于 2023-1-9 11:54:41
发表于 2023-1-9 11:54:41