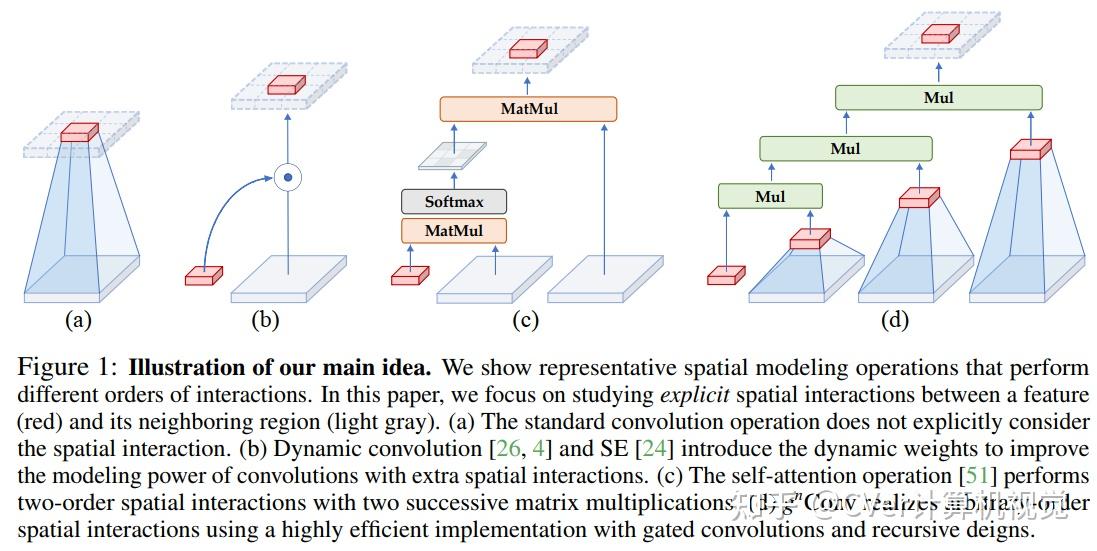
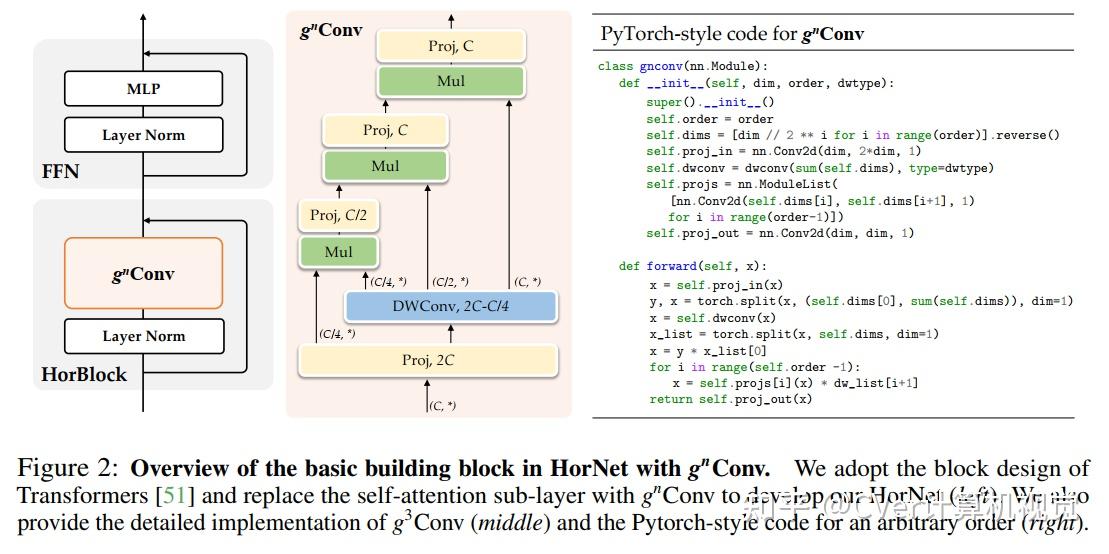
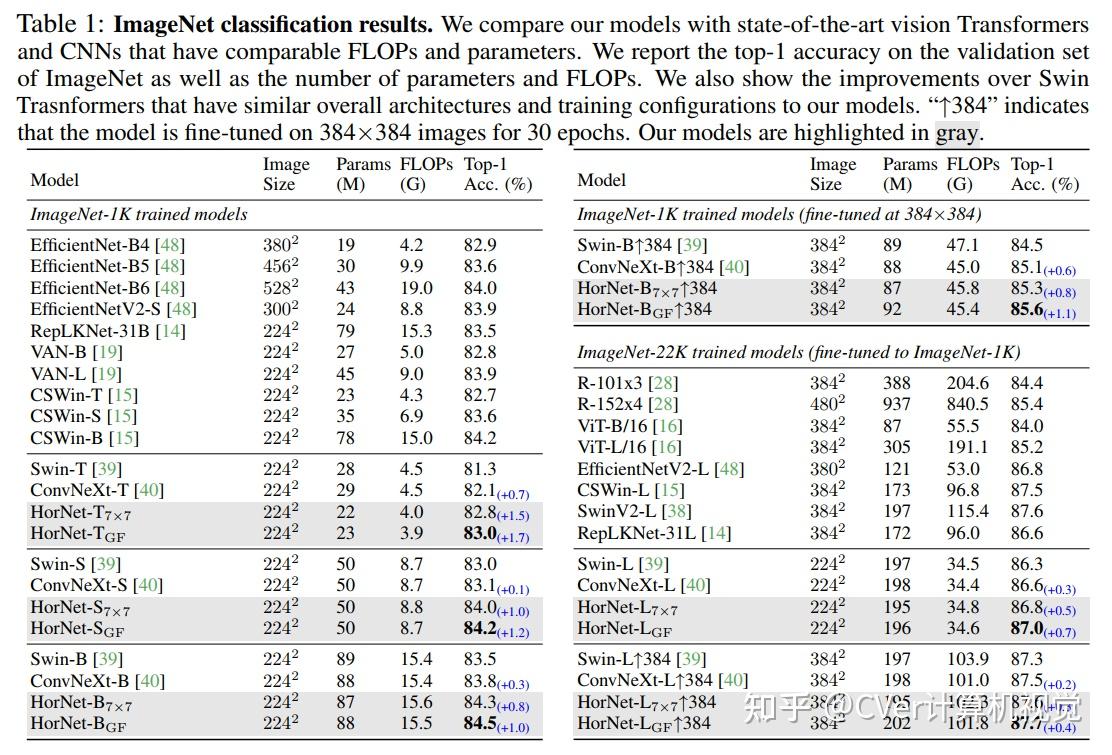
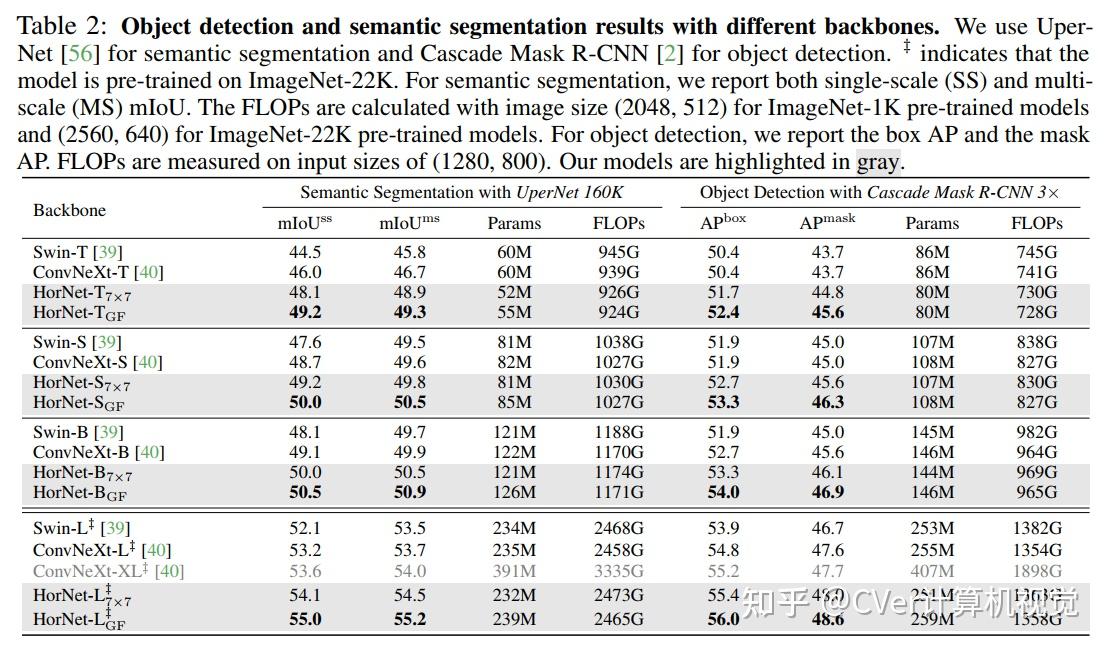
2
4
7
新手上路
单位:清华(鲁继文团队), Meta AI 代码:https://github.com/raoyongming/HorNet 论文:https://arxiv.org/abs/2207.14284
使用道具 举报
10
18
0
5
9
本版积分规则 发表回复 回帖后跳转到最后一页


 发表于 2022-9-22 03:29:15
发表于 2022-9-22 03:29:15