|
|
C++11 之前,C++原生不支持并行与并发。但这并不意味着无法对线程进行操作, 只不过需要使用系统库的API进行操作(因为线程与操作系统是不可分开的)。随着C++11标准的完成,我们有了 std::thread ,其能给予我们可以在所有操作系统 上可移植的线程操作。为了同步线程,C++11也添加了互斥量,并且对一些RAII类 型的锁进行了封装。另外,std::condition_variable 也能够灵活的在线程间,进行 唤醒操作。另一些有趣的东西就是 std::async 和 std::future ——我们可以将普通的函数封装 到 std::async 中,可以在后台异步的运行这些函数。包装后函数的返回值则 用 std::future 来表示,函数的结果将会在运行完成后,放入这个对象中,所以可以在函数完成前,做点别的事情。
让程序在特定时间休眠
C++11中对于线程的控制非常优雅和简单。在 this_thread 的命名空间中,包含了只 能被运行线程调用的函数。其包含了两个不同的函数,让线程睡眠一段时间,这样就不需要使用任何额外的库,或是操作系统依赖的库来执行这个任务。 本节中,我们将关注于如何将线程暂停一段时间,或是让其休眠一段时间。
#include <chrono>
#include <iostream>
#include <thread>
using namespace std;
using namespace chrono_literals;
int main() {
cout << &#34;sleep for 5s + 300ms&#34;;
this_thread::sleep_for(5s + 300ms);
cout << &#34;sleep for 3s&#34;;
this_thread::sleep_until(chrono::high_resolution_clock::now() + 3s);
}
这是可以运行的程序,其中sleep_for 和 sleep_until 函数都已经在 C++11 中加入,存放于std::this_thread命名空间中。其能对当前线程进行限时阻塞(并不是整个程序或整个进程)。线程被阻塞时不会消耗CPU时间,操作系统会将其标记挂起的状态,时间到了后线程会自动醒来。这种方式的好处在于,不需要知道操作系统对我们运行的程序做了什么,因为 STL会将其中的细节进行包装。 this_thread::sleep_for 函数能够接受一个 chrono::duration 值。最简单的方式就是 1s或 5s+300ms。为了使用这种非常简洁的字面时间表示方式,我们需要对命名空间进行声明 using namespace std::chrono_literals; 。this_thread::sleep_until 函数能够接受一个 chrono::time_out 参数。这就能够简单的指定对应的壁挂钟时间,来限定线程休眠的时间。 对于那种新型写法,我查了一下大概是 c++ 11 引进得 User-defined literals , 允许用户自定义后缀产生相应的对象,具体可以看这个网址:https://en.cppreference.com/w/cpp/language/user_literal
启动和停止线程
C++11中添加了 std::thread 类,并能使用简洁的方式能够对线程进行启动或停止, 线程相关的东西都包含在STL中,并不需要额外的库或是操作系统的实现来对其进行支持。 本节中,我们将实现一个程序对线程进行启动和停止。如果是第一次使用线程的话,就需要了解一些细节。
#include <chrono>
#include <iostream>
#include <thread>
using namespace std;
using namespace chrono_literals;
static void thread_with_param(int i) {
this_thread::sleep_for(1ms * i);
cout << &#34;线程 &#34; << i << &#34;开始 \n&#34;;
this_thread::sleep_for(1s * i);
cout << &#34;线程 &#34; << i << &#34;结束\n&#34;;
}
int main() {
cout << thread::hardware_concurrency()
<< &#34;个线程在当前所使用的系统中能够同时运行.\n&#34;;
thread t1{thread_with_param, 1};
thread t2{thread_with_param, 2};
thread t3{thread_with_param, 3};
t1.join();
t2.join();
t3.detach();
cout << &#34;Threads joined.\n&#34;;
}
- 主函数中,会先了解在所使用的系统中能够同时运行多少个线程,使用 std::thread::hardware_concurrency 进行确定。这个数值通常依赖于机器上有 多少个核,或是STL实现中支持多少个核。这也就意味着,对于不同机器,这 个函数会返回不同的值.
- 这里我们启动三个线程。 我们使用实例化线程的代码行为 thread t {f, x},这就等于在新线程中调用 f(x) 。这样,在不同的线程中就可以给于 thread_with_param 函数不同的参数。
- 当启动线程后,我们就需要在其完成其工作后将线程进行终止,使用 join 函数来停止线程。调用 join 将会阻塞调用线程,直至对应的线程终止为止
- 另一种方式终止的方式是分离。如果不以 join 或 detach 的方式进行终止,那 么程序只有在 thread 对象析构时才会终止。通过调用 detech ,我们将告诉3号线程,即使主线程终止了,你也可以继续运行。这个是cppreference 的意思,可是经过我的测试和查询,join 和 detach 仅仅只是回收资源的方式不一样,join 是由主线程回收,detach 则是由运行时库负责清理被调线程相关的资源,主线程结束后,所有相关的子线程都会结束。
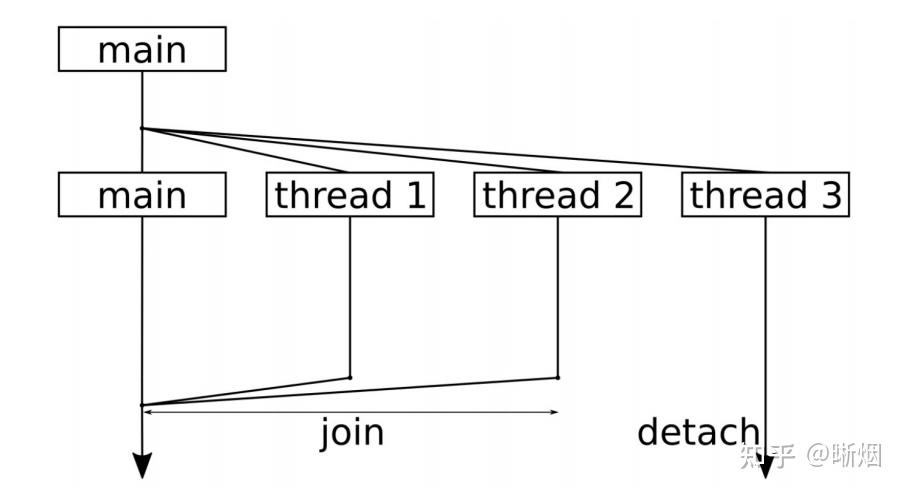
image.png
互斥量(mutex)

image.png
线程对互斥量上锁之后,很多事情都变的非常简单,我们只需要上锁、访问、解锁 三步就能完成我们想要做的工作。不过对于有些比较健忘的开发者来说,在上锁之 后,很容易忘记对其进行解锁,或是互斥量在上锁状态下抛出一个异常,如果要对 这个异常进行处理,那么代码就会变得很难看。最优的方式就是程序能够自动来处理这种事情。 内存管理部分,我们有 unique_ptr , shared_ptr 和 weak_ptr 。这些辅助类可以很完美帮我们避免内存泄漏。互斥量也有类似的帮手,最简单的一个就是 std::lock_guard 。使用方式如下:
void critical_function() {
lock_guard<mutex> l{some_mutex};
// critical section
}
lock_guard 的构造函数能接受一个互斥量,其会立即自动调用 lock ,构造函数会直到获取互斥锁为止。当实例进行销毁时,其会对互斥量再次进行解锁。这样互斥量就很难陷入到 lock/unlock 循环错误中。 C++17 STL提供了如下的RAII辅助锁。其都能接受一个模板参数,其与互斥量的类型相同(在C++17中,编译器可以自动推断出相应的类型):
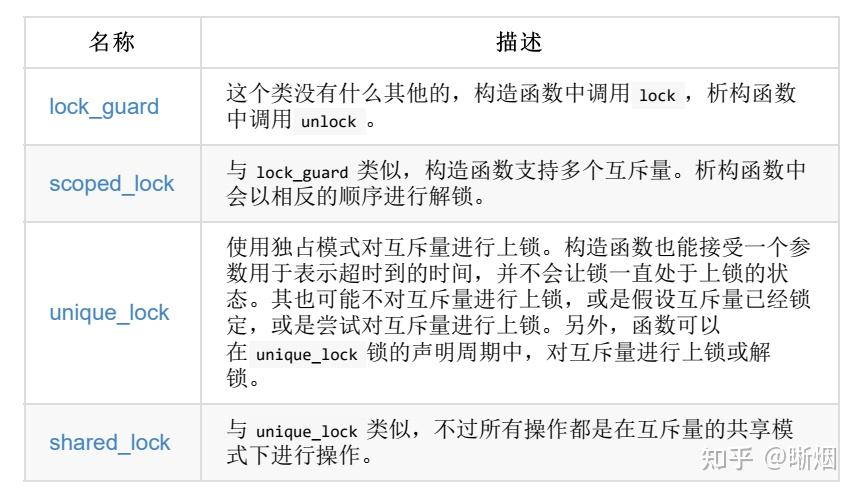
image.png
scoped_lock 能够避免死锁的发生。 std::scoped_lock的预防死锁策略很简单,假设要对 n 个 mutex(mutex1, mutex2, ..., mutexn)上锁,那么每次只尝试对一个 mutex 上锁,只要上锁失败就立即释放获得的所有锁(方便让其他线程获得锁),然后重新开始上锁,处于一个循环当中,直到对 n 个 mutex 都上锁成功。这种策略是基本上是有效的,虽然有极小的概率出现“活锁”,例如ABBA死锁中,线程1释放锁A的同一时刻时线程2又释放了锁B,然后这两个线程又同时分别获得了锁A和锁B,如此循环。
进行延迟初始化——std::call_once
假如我们将完成一个程序,我们使用多线程对同一段代码进行执行。他们执行的是相同的代码,但是我们的初始化函数只需要运行一次:
#include <iostream>
#include <mutex>
#include <thread>
#include <vector>
using namespace std;
// 在对指定函数使用 call_once 时,需要对所有线程进行同步,这是同步标志
once_flag callflag;
// 只需要执行一次的函数
static void once_print() { cout << &#39;!&#39;; }
static void print(size_t x) {
// 只调用一次的写法
std::call_once(callflag, once_print);
cout << x;
}
int main() {
vector<thread> v;
for (size_t i{0}; i < 10; ++i) {
v.emplace_back(print, i);
}
for (auto &t : v) {
t.join();
}
cout << &#39;\n&#39;;
}
std::call_once 工作原理和栅栏类似:第一个线程达到 call_once 的线程会执行对应的函数,其他线程到这就阻塞。当第一个线程从准备函数中返回后,其他线程才结束阻塞。我们可以对这个过程进行安排,让一个变量决定其他线程能否运行,线程则必须对这个变量进行等待,直到这个变量准备好了,所有变量才能运行。这个变量就 是 once_flag callflag;。每一个 call_once 都需要一个 once_flag 实例作为参数,来 表明预处理函数是否运行了一次。 另一个细节是:如果 call_once 执行失败了(因为准备函数抛出了异常),那么下一个线程则会再去尝试执行。
将执行的程序推到后台——std::async
前面说过的 t1.join(),并不会给你返回值,为了获取返回值通常只能运用共享内存的方法。 C++11之后, std::async 能帮我们完成这项任务。我们将写一个简单的程序,并使用异步函数,让线程在同一时间内做很多事情。 std::async 其实很强大,让我们先来了解其一方面。
#include <algorithm>
#include <future>
#include <iomanip>
#include <iostream>
#include <iterator>
#include <map>
#include <string>
using namespace std;
// 对字符串中的字符进行统计
static map<char, size_t> histogram(const string &s) {
map<char, size_t> m;
for (char c : s) {
m[c] += 1;
}
return m;
}
// 返回一个排序后的副本
static string sorted(string s) {
sort(begin(s), end(s));
return s;
}
// 是否元音字母
static bool is_vowel(char c) {
char vowels[]{&#34;aeiou&#34;};
return end(vowels) != find(begin(vowels), end(vowels), c);
}
// 对传入的字符串中元音字母进行计数
static size_t vowels(const string &s) {
return count_if(begin(s), end(s), is_vowel);
}
int main() {
// 测试变量
string input = &#34;wakwkdawfkwekf&#34;;
// 函数一
auto hist(async(launch::async, histogram, input));
// 函数二
auto sorted_str(async(launch::async, sorted, input));
// 函数三
auto vowel_count(async(launch::async, vowels, input));
// 获取函数一的返回值
for (const auto &[c, count] : hist.get()) {
cout << c << &#34;: &#34; << count << &#39;\n&#39;;
}
// 获取函数 二 三 的返回值
cout << &#34;Sorted string: &#34; << sorted_str.get() << &#39;\n&#39;
<< &#34;Total vowels: &#34; << vowel_count.get() << &#39;\n&#39;;
}
通过 std::async 会返回一个 future 类型对象。这个对象表示在未来某个时间点上,对象将会获取返回值。通过对 future 对象使 用 .get() ,我们将会阻塞主函数,直到相应的值返回。 我们将三个函数使用 async(launch::async, ...) 进行包装。这样三个函数都不会由主函数来完成。此外, async 会启动新线程,并让线程并发的完成这几个函数。这样我们只需要启动一个线程的开销,就能将对应的工作放在后台进行,而后可以继续执行其他代码。 launch::async 是一个用来定义执行策略的标识。其有两种独立方式和一种组合方式:
| 策略选择 | 意义 | | std::launch::async | 运行新线程,以异步执行任务 | | std::launch::deferred | 在调用线程上执行任务(惰性求值)。在对 future 调用 get 和 wait 的时候,才进行执行。如果什么都没有发生,那么执行函数就没有运行。 |
不使用策略参数调用 async(f, 1, 2, 3) , async 的实现可以自由的选择策略。这也就意味着,我们不能确定任务会执行在一个新的线程上,还是执行在当前线程上。
还有件事情我们必须要知道,假设我们写了如下的代码:
async(launch::async, f);
async(launch::async, g);
这就会让 f 和 g 函数并发执行(这个例子中,我们并不关心其返回值)。运行这段代码时,代码会阻塞在这两个调用上,这并不是我们想看到的情况。 所以,为什么会阻塞呢? async 不是非阻塞式、异步的调用吗?没错,不过这里有点特殊:当对一个 async 使用 launch::async 策略时,获取一个 future 对象,之后其析构函数将会以阻塞式等待函数结束运行。 这也就意味着,这两次调用阻塞的原因就是, future 生命周期只有一行的时间!我们可以以接收其返回值的方式,来避免这个问题,从而让 future 对象的生命周期更长。
条件变量(condition_variable)
下面是例子(生产者消费者模型):
#include <condition_variable>
#include <iostream>
#include <queue>
#include <thread>
#include <tuple>
using namespace std;
using namespace chrono_literals;
queue<size_t> q;
mutex mut;
condition_variable cv;
bool finished{false};
// 生产者
static void producer(size_t items) {
for (size_t i{0}; i < items; ++i) {
this_thread::sleep_for(100ms);
{
lock_guard<mutex> lk{mut};
q.push(i);
}
cv.notify_all();
}
{
lock_guard<mutex> lk{mut};
finished = true;
}
cv.notify_all();
}
// 消费者
static void consumer() {
while (!finished) {
unique_lock<mutex> l{mut};
cv.wait(l, [] { return !q.empty() || finished; });
while (!q.empty()) {
cout << &#34;Got &#34; << q.front() << &#34; from queue.\n&#34;;
q.pop();
}
}
}
int main() {
thread t1{producer, 10};
thread t2{consumer};
t1.join();
t2.join();
cout << &#34;finished!\n&#34;;
}
我们只启动了两个线程。第一个线程会生产一些商品,并放到队列中。另 一个则是从队列中取走商品。当其中一个线程需要对队列进行访问时,其否需要对公共互斥量 mut 进行上锁,这样才能对队列进行访问。这样,我们就能保证两个线程不能再同时对队列进行操作。
cv.wait(lock, predicate) 将会等到 predicate() 返回true时,结束等待。不过其不会对 lock 持续的进行解锁与上锁的操作。为了将使用 wait 阻塞的线程唤醒,我们就需要使用 condition_variable 对象,另一个线程会对同一个对象调用 notify_one() 或 notify_all() 。等待中的线程将从休眠中醒来,并检查 predicate() 条件是否成立。 这样的操作很方便我们使用,因为一般情况下需要多行代码,当消费者被 notify 起来后,可能不止你一个消费者被激活,为保证条件仍就能够合理消费,需要对临界条件再次检查,该 wait函数的用法浓缩了这几行代码。
C++17 线程池
前置知识
返回值类型推导 result_of 和 invoke_result
result_of 是在 C++11 中引入的,同时由于自身原因于C++20 中移除,替代品为 C++17 中引入的 invoke_result,result_of我觉得很难用,从下面例子可以看出来,泛型的类别我很难写,下面那个 ri 函数,我想着直接用函数的类型,但是不行,会报错,要以下面那种奇怪的写法写出来,而invoke_result就很合理,所以接下来的线程池会采用 invoke_result 来参与返回值获取的实现.
#include <iostream>
using namespace std;
int r1() { return 1; }
result_of<decltype(r1)&(void)>::type i = 1;
invoke_result<decltype(r1)>::type s = 1;
int main() { cout << i; }
packaged_task
类模板 std::packaged_task 包装任何可调用目标(函数、 lambda 表达式、 bind 表达式或其他函数对象),使得能异步调用它。其返回值或所抛异常被存储于能通过 std::future 对象访问的共享状态中。
下面是例子:
#include <iostream>
#include <cmath>
#include <thread>
#include <future>
#include <functional>
// 避免对 std::pow 重载集消歧义的独有函数
int f(int x, int y) { return std::pow(x,y); }
void task_lambda()
{
std::packaged_task<int(int,int)> task([](int a, int b) {
return std::pow(a, b);
});
std::future<int> result = task.get_future();
task(2, 9);
std::cout << &#34;task_lambda:\t&#34; << result.get() << &#39;\n&#39;;
}
void task_bind()
{
std::packaged_task<int()> task(std::bind(f, 2, 11));
std::future<int> result = task.get_future();
task();
std::cout << &#34;task_bind:\t&#34; << result.get() << &#39;\n&#39;;
}
void task_thread()
{
std::packaged_task<int(int,int)> task(f);
std::future<int> result = task.get_future();
std::thread task_td(std::move(task), 2, 10);
task_td.join();
std::cout << &#34;task_thread:\t&#34; << result.get() << &#39;\n&#39;;
}
int main()
{
task_lambda();
task_bind();
task_thread();
}
线程池代码
#include <condition_variable>
#include <functional>
#include <future>
#include <memory>
#include <mutex>
#include <queue>
#include <stdexcept>
#include <thread>
#include <vector>
class ThreadPool {
public:
ThreadPool(size_t);
template <class F, class... Args>
auto enqueue(F &&f, Args &&...args)
-> std::future<typename std::invoke_result<F>::type>;
~ThreadPool();
private:
// need to keep track of threads so we can join them
std::vector<std::thread> workers;
// the task queue
std::queue<std::function<void()>> tasks;
// synchronization
std::mutex queue_mutex;
std::condition_variable condition;
bool stop;
};
// the constructor just launches some amount of workers
inline ThreadPool::ThreadPool(size_t threads) : stop(false) {
for (size_t i = 0; i < threads; ++i)
workers.emplace_back([this] {
for (;;) {
std::function<void()> task;
{
std::unique_lock<std::mutex> lock(this->queue_mutex);
// 等生产者生产
this->condition.wait(
lock, [this] { return this->stop || !this->tasks.empty(); });
// 若是因为内存池停止,或是虚假唤醒 直接 return
if (this->stop && this->tasks.empty())
return;
// 拿任务
task = std::move(this->tasks.front());
this->tasks.pop();
}
task();
}
});
}
// add new work item to the pool
template <class F, class... Args>
auto ThreadPool::enqueue(F &&f, Args &&...args)
-> std::future<typename std::invoke_result<F>::type> {
// std::invoke_result 用于推导可调用对象的放回值类型
using return_type = typename std::invoke_result<F>::type;
// 将获取 packaged_task
auto task = std::make_shared<std::packaged_task<return_type()>>(
std::bind(std::forward<F>(f), std::forward<Args>(args)...));
std::future<return_type> res = task->get_future();
{
std::unique_lock<std::mutex> lock(queue_mutex);
// don&#39;t allow enqueueing after stopping the pool
if (stop)
throw std::runtime_error(&#34;enqueue on stopped ThreadPool&#34;);
tasks.emplace([task]() { (*task)(); });
}
condition.notify_one();
return res;
}
// the destructor joins all threads
inline ThreadPool::~ThreadPool() {
{
std::unique_lock<std::mutex> lock(queue_mutex);
stop = true;
}
condition.notify_all();
for (std::thread &worker : workers)
worker.join();
}
测试函数
#include <iostream>
#include <vector>
#include <chrono>
#include &#34;ThreadPool.h&#34;
int main()
{
ThreadPool pool(4);
std::vector< std::future<int> > results;
for(int i = 0; i < 8; ++i) {
results.emplace_back(
pool.enqueue( {
std::cout << &#34;hello &#34; << i << std::endl;
std::this_thread::sleep_for(std::chrono::seconds(1));
std::cout << &#34;world &#34; << i << std::endl;
return i*i;
})
);
}
for(auto && result: results)
std::cout << result.get() << &#39; &#39;;
std::cout << std::endl;
return 0;
} |
|


 发表于 2023-1-17 00:30:03
发表于 2023-1-17 00:30:03